 消息未读数服务方案
消息未读数服务方案
# 背景
消息未读数是目前网络应用很常见的功能,系统消息、@消息、私信等各种各样的消息,只要是个消息就会有一个已读和未读的状态。本文主要针对这个未读数的设计方案做思考和讨论。
# 需求分析
对所有消息的已读未读状态做统计展示,产生新消息未读数+1,已读消息未读数-1。
根据消息的类型标记已读又分两种策略:
- 自动标记类:当用户查看到消息的时候就已经是已读,如群聊、私信、社区资讯等。
- 手动标记类:用户可以手动标记内容为已读,通常通过点击未读标记来实现,如系统消息、站内通知等。
# 技术实现思路
# 模型设计
我们先根据不同的未读数策略确定大致的数据库模型:
# 自动标记类
需要一张用户访问记录表: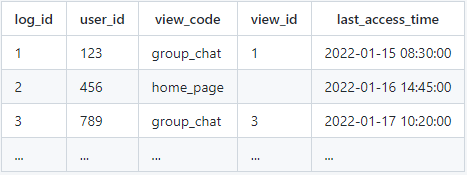
- log_id:唯一主键
- user_id:用户ID,用于标识用户。
- view_code:访问视图的代号,用于标识不同的视图。
- view_id:视图主体ID,用于标识具体的视图主体。
- last_access_time:最近一次访问时间,记录用户最新访问的时间。
CREATE TABLE user_access_log (
log_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
view_code VARCHAR(255) NOT NULL,
view_id INT NOT NULL,
last_access_time TIMESTAMP NOT NULL,
UNIQUE KEY (user_id, view_code, view_id)
);
2
3
4
5
6
7
8
这样我们数据库查询未读数的时候,只需要使用当前用户上一次访问这个视图的时间,去查询这个视图实体下有多少条数据的创建时间在这个时间之后,就可以确定未读数的数量。
比如表中的home_page首页,就好比微博首页,通过判断当前用户的last_access_time来确定在这个时间之前首页的新消息,如果展示上有最大数限制可以在sql的最后加上limit限制,防止查询多余的数据。
如果要细化到某个群聊或者是私信,就可以用到view_id来进行隔离。
# 手动标记类
需要两张表,消息主表和用户消息表:
消息主表
- message_id: 消息的唯一标识,作为主键。
- message_title: 消息的标题,限制最大长度为255个字符,并且不能为空。
- message_content: 消息的内容,可以存储较长的文本信息。
- message_type:消息类型,用来标识不同类型的消息。
- read_count: 已读人数,用于记录消息被阅读的次数,默认为0。
- created_time: 创建时间,记录消息的创建时间,默认为当前时间戳。
- modified_time: 修改时间,记录消息的修改时间,当消息被修改时更新为当前时间戳。
CREATE TABLE message (
message_id INT PRIMARY KEY,
message_title VARCHAR(255) NOT NULL,
message_content TEXT NOT NULL,
message_type INT DEFAULT 1,
read_count INT DEFAULT 0,
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
modified_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
2
3
4
5
6
7
8
9
用户消息表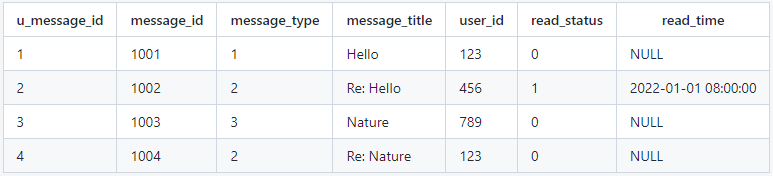
- u_message_id:用户消息的唯一标识,采用自增主键。
- message_id:消息主体id。
- message_type:主消息类型。
- message_title:主消息标题,用于展示给用户的信息。
- user_id:用户id,用于关联特定用户。
- read_status:消息的已读未读状态,采用bitmap表示。
- read_time:消息的已读时间,采用时间戳类型表示。
CREATE TABLE user_messages (
u_message_id INT PRIMARY KEY AUTO_INCREMENT,
message_id INT NOT NULL,
message_type TINYINT NOT NULL,
message_title VARCHAR(255) NOT NULL,
user_id INT NOT NULL,
read_status TINYINT UNSIGNED NOT NULL,
read_time TIMESTAMP
);
2
3
4
5
6
7
8
9
这样我们数据库查询未读数的时候就可以直接查询用户消息表,用read_status区分已读未读来计数。
# 未读数查询优化
无论是上面的哪种策略,在sql层面未读数的统计与计算都是需要执行group语句去分组统计,这个性能是很低的,所以我们肯定需要利用到缓存机制,大致架构如下: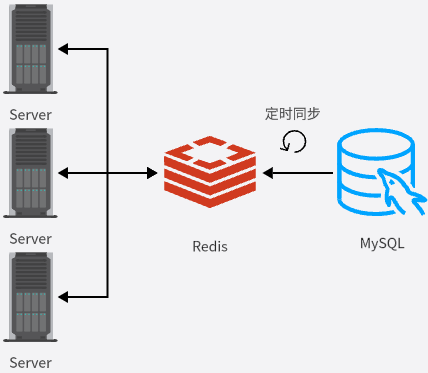
基本思路就是应用节点产生新消息时,对未读数进行入库,入库成功后Redis计数+1,查询时直接查Redis。具体实现我们两个策略分开讨论:
# 自动标记类
对于群聊、私信这种自动标记类消息,有写扩散和读扩散两种方案:
说明
读扩散:多请求读取某个数据时,各自计算自己的那份;写入性能高,读取性能差。
写扩散:更新数据时,直接计算好所有人的结果,读取时直接返回无需计算;写入性能差,读取性能高。
一、写扩散计数
需要两个缓存
- 群聊未读数(map):
uid:[{群聊id,未读数}], - 汇总的数量(map):
uid:[{首页,未读数},{群聊,未读数}]
当产生新消息时,群聊id对应的未读数+1,总未读数+1,并且这里的操作需要保证原子性,防止群聊未读数+1但总未读数+1失败,解决方案是使用lua脚本来进行更新。已读操作则是当访问和离开当前群聊的时候对缓存进行归零。
注意
这里存在一个问题,假设我群聊有500人,有100人非常活跃,相当于里面多一条消息就得去更新剩下400个人的缓存,我认为这是不合理的,因为这类消息是高频的,仅当获取的时候消耗CPU资源去计算未读数即可。
二、读扩散计数
需要两个缓存
- 群聊访问时间(map):
uid:[{群聊id,上一次访问时间戳}] - 群聊消息的缓存(list):
群聊id:[消息1时间戳,消息2时间戳]
当用户获取未读数的时候,根据上一次访问该群聊的时间戳查询当前群聊id的消息缓存有多少条消息时间戳在这之前就是未读数,总未读数则是这些群聊的总和。这样在高频的消息创建时只需要在群里消息缓存中添加消息的时间戳即可。
并且对内存再进一步优化的话,就是根据需求对一个群聊能存储的时间戳上限进行限制,如显示上限为99+,则一个群聊消息缓存只保留最新的99个时间戳,计算总未读数的时候若显示上限为99+同样是累加至99时直接返回,不进行过多的计算。然后仅在用户获取未读数时才触发这个汇总计算。已读操作则是在访问和离开当前群聊的时候更新上一次访问时间戳。
# 手动标记类
对于邮件、系统消息这种手动标记类消息,处理就比较简单了,
Redis使用map存储uid:[{消息类型,未读数}],发送新消息时对应的消息类型+1,总数+1,已读则-1,因为这类消息是低频的,所以不需要担心缓存操作过于频繁的问题。
# 风险处理
这里我们考虑一下极端情况,因为我们的未读数获取是重依赖缓存的,当Redis挂掉的时候我们需要设置默认值来兜底,通过服务熔断、降级等策略,防止出现缓存雪崩和穿透的情况。
利用到了缓存和数据库,那就避免不了存在数据一致性问题,考虑极端情况,因为我们的缓存未读数增加是在数据库入库成功之后,所以我们直接考虑Redis更新失败的情况,那无非是存在一定时间内的数据不一致,我们只要保证一定时间内保证数据最终一致性即可,所以我们增加一个数据库定时同步的机制去同步缓存,但是这里用户量过大的话也会导致这个同步机制的负担过大,所以可以针对一些活跃群聊或者是活跃用户分批的去更新。